Find DAC
The Find dynamic advanced command is part of the variable commands. Use this command to find the position of specific text within a variable or to search for and retrieve all matches of a pattern defined by a regular expression (regex). A regex is a sequence of characters that defines a search pattern, useful for identifying specific text patterns within larger bodies of text. Drag the command into a wizard from the Advanced commands view in the Nintex Wizard Editor to use it.
Before you begin:
Learn how to navigate the Nintex Wizard Editor of the Studio.
Understand how to create wizards and use advanced commands.
Understand variables.
Learn how to customize error handling within an advanced command.
Understand how to configure wizard fallbacks.
Use the Find command to enhance your automation in various scenarios:
-
Locate the position of a specific substring within a variable.
-
Identify all instances of text that match a regular expression.
-
Handle text searches with options for case sensitivity and close (fuzzy) matching.
-
Enhance accuracy with scanned documents or OCR (Optical Character Recognition) outputs, where similar-looking characters like "1" and lowercase "l" need to be matched despite minor differences.
-
Combine with the Split command to locate a specific section of text within a variable, then split the text into two parts based on the identified position, storing each part in separate variables. See Example.
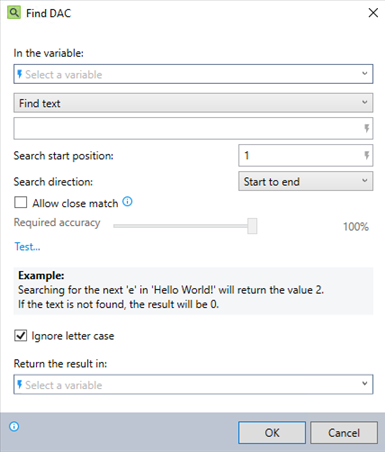
In the Nintex Wizard Editor, search for the Find command and drag it into your steps. Use the table below to configure each field and understand the settings:
| Field | Description | What to do | |
|---|---|---|---|
| In the variable | The name of the variable where you want to perform the search. | Enter the variable name. | |
| Find text | Find text |
The specific text to search for. The wizard returns the position of the first character it finds, counting from the top left corner and including spaces. If it doesn't find the text, it returns the value 0. |
Enter the text you want to find (this can be free text or values from other variables). |
| Search start position | The character position within the variable where the search should begin. | Define the starting position (e.g., 1 for the beginning of the variable). | |
| Search direction | The direction in which the search should be conducted. | Choose Start to end or End to start. | |
| Allow close match | Allows flexibility in matching visually similar characters (e.g., 1 and l). | Select this option to allow close matches. | |
| Require accuracy | A slider that controls how closely characters must resemble each other to count as a match. The slider becomes available when you select Allow close match; otherwise, it remains greyed out. | Adjust the slider to set the required accuracy level for matching. For detailed examples of how this works, see the How close does the match need to be? section. | |
| Ignore letter case |
Specifies whether the search should ignore case when matching text. This option is disabled when you select Allow close match.
|
Select the checkbox to ignore letter case. If unchecked, the search matches only text with the same case as entered. |
|
| Find text matching a regular expression | Find text matching a regular expression | An option to search for text that matches a specific regular expression pattern. | Select this option if you need to search using a regular expression. |
| Search type |
Defines the search method when using regular expressions:
|
Choose either Full match or Capture groups depending on the complexity of your regex search. | |
| Pattern | The regular expression pattern used to find matching text. | Enter the regex pattern. This can include free text, variables, and line breaks. | |
| Match delimiter | The character used to separate each matching text found. | Enter the delimiter (e.g., semicolon ;). If using Capture groups, specify both group and match delimiters. | |
| Regex options | Provides additional controls over how the regular expression search is performed. This includes options for case sensitivity, multiline processing, and more. | Select the appropriate option based on your search requirements. See Regex options for a description of each option. | |
| Test... | A feature to check your text matching criteria, including close matches and regular expressions, against sample data. | (Optional) Use the Close match tester to ensure the text matching criteria, including regex, provide the expected results. | |
| Return the result in | The name of the variable to store the search result. | Enter the name of the variable to store the search result (returns the position of the found text). | |
The Close match tester helps you check how closely your source text matches the target text by adjusting accuracy settings. This tool highlights all instances of the text you enter in the Text to find field, focusing on whole words instead of characters. It's especially useful for scanned documents or when characters look similar but aren’t identical. You can access this tool within the Find command by clicking the Test... link, as shown in the Command setup.
What is a close match?
A close match (or fuzzy match) allows for flexibility in matching text by considering characters that look similar. For example, the number "1" and the lowercase letter "l" often get confused because they look alike. This feature is important when it's hard to tell characters apart, like with scanned documents or OCR outputs.
How close does the match need to be?
The Required accuracy slider controls how similar characters must be to count as a match. You can adjust this slider to set how closely the characters need to resemble each other.
For example:
-
High accuracy setting: If you set the slider high, the wizard might match "c1ose" with "close" because the number "1" looks similar to the lowercase "l". This setting ignores small visual differences when the characters are almost the same.
-
Lower accuracy setting: If you set the slider lower, the wizard might not match "ad ress" with "address" because the blank space doesn’t look like the lowercase "d". Lowering the accuracy allows for more differences between characters to still count as a match.
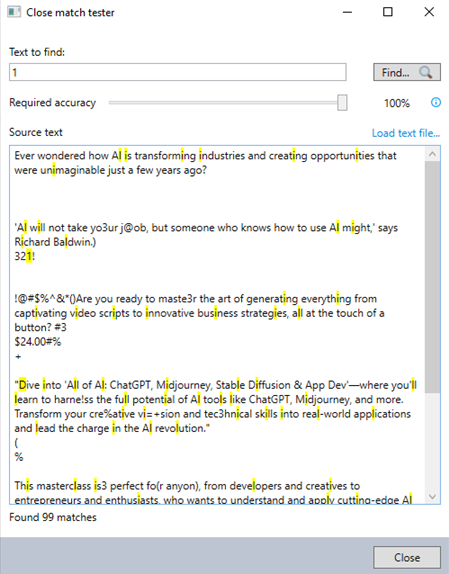
Use the table below to configure each field accurately and understand the settings:
| Field | Description | What to do |
|---|---|---|
| Text to find | The text string you want to search for in the source text. | Enter the specific text you want to find. |
| Required accuracy | A slider that determines how visually similar the characters need to be to count as a match (0-100%). | Adjust the slider to set the required accuracy level for matching. |
| Source text | The text where the search happens. | Enter or paste the text you want to search through. |
| Load text file... | An option to upload a text file from your computer to use as the source text. | Click this option to browse and upload a text file from your computer. |
| Find... | Runs the search based on the specified criteria in the source text. | Click Find... to execute the search and view results according to your accuracy settings. |
The Regular expression tester helps you test the behavior of regular expressions (regex) by searching through source text and displaying results based on the regex pattern you define. This tool is available only when you select the Find text matching a regular expression option. Clicking Test... opens the tester. Use it to verify if a specific pattern or set of patterns match text within your source material.
The Replace text option allows you to change text in your source, but it's not relevant to this command, so you can disregard it.
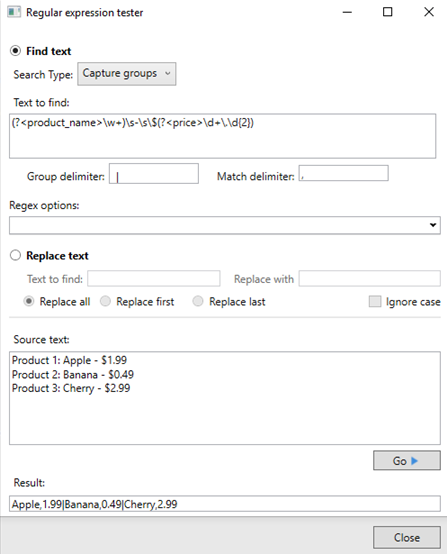
Use the table below to configure each field accurately and understand the settings:
| Field | Description | What to do | |
|---|---|---|---|
| Search Type | Option to choose between Full match (finds all matching text in the source) or Capture groups (returns grouped matches based on your regex pattern). | Select whether you want to match the entire expression or capture groups within the pattern. | |
| Text to find | The regex pattern you want to use to search the source text. | Enter the regex pattern. For Capture groups, define named groups like this: (?<groupname>pattern). | |
| Full match | Delimiter | The character that separates each match found in the text. The default is a comma if left empty. | Enter the delimiter to separate each match. |
| Capture groups | Group delimiter | The character that separates each group result. The default is a pipe (|) if left empty. | Enter the delimiter to separate group results. |
| Match delimiter | The character that separates the individual matches within each group. The default is a comma if left empty. | Enter the delimiter to separate individual matches within a group. | |
| Regex options | Option to fine-tune the regex search behavior. The default is the Ignore case option. | Choose any relevant regex options (e.g., Ignore case) to control how the search works. For more details on these options, see the [Regex options section]. | |
| Source text | The text where the search happens. | Enter or paste the text you want to search through. | |
| Go > | Runs the search using the defined regex pattern and displays the results in the Result field. | Click to run the search and display results based on your regex pattern and settings. | |
| Result | Where the search matches or capture groups are shown. | After running the search, the tool displays the matching data here, separated by your specified delimiters. | |
The Regex options provide additional control over how the regular expression search is performed within the Find command. These options allow you to fine tune your search parameters, ensuring greater flexibility and precision depending on your specific needs. These options are only available when selecting Find text matching a regular expression. You can select multiple regex options to customize your search further. The table below outlines each option, along with a brief description and guidance on when and how to use them effectively in your text searches.
| Field | Description | What to do |
|---|---|---|
| Ignore case | Makes the regex search case-insensitive, allowing matches regardless of whether the text is uppercase or lowercase. |
Select this option to match text regardless of case (e.g., "Support@example.com" and "support@example.com") using a pattern like [A-Z]+@[example\.com]. By default, the regular expression engine is case-sensitive, meaning it will only match text that exactly matches the case of the characters in the regex pattern.
|
| Multi-line | Treats input text as multiple lines, where ^ and $ match the start and end of each line. | Select this option to match patterns across individual lines in multi-line text (e.g., ^Hello for line starts). |
| Single line | Changes the behavior of the dot (.) to match every character, including newline characters. | Select this to treat the entire text as a single line, useful for matching patterns across multiple lines. Useful for patterns like Hello.*World. |
| Explicit captures only | Restricts regex to capture groups marked with parentheses, ignoring non-capturing groups. | Select this option to capture specific groups only (e.g., (?<name>[A-Z]+) for capturing uppercase letters). |
| Compiled | Precompiles the regex for faster execution, useful for repeated use of the same pattern. | Select this to improve performance when reusing the same regex multiple times. |
| Ignore white space | Ignores whitespace and comments in the regex pattern, allowing for more readable patterns. | Select this option when writing complex regex patterns that require spaces or comments for clarity. For example, (?x) ([A-Z]+) ignores spaces inside the pattern and match uppercase letters. |
| Right-to-left mode | Reverses the direction of the search, scanning from right to left instead of the usual left to right. | Select this to search text from the end to the beginning, useful for certain processing scenarios. |
| ECMAScript matching behavior | Ensures that the regex follows ECMAScript (JavaScript) rules. | Select this to ensure regex behaves exactly like it would in a JavaScript environment. |
| Comparison using the invariant culture | Forces the comparison to ignore cultural variations, ensuring consistent behavior across different locales. | Select this to compare strings consistently regardless of regional settings, such as when matching specific formatting rules. |
Additional resources for regular expressions
If you’re new to regular expressions or want to deepen your understanding, here are some useful resources:
-
For comprehensive information and tutorials on regular expressions, visit the Microsoft Developer Network (MSDN) Regular Expressions page. This resource provides in-depth explanations and examples on how to effectively use regex in different programming environments.
-
Use an online regex tester like Regex101. This website allows you to test your regular expressions in real-time and provides detailed explanations of each part of your regex pattern, making it easier to understand and debug.
Follow these best practices when using the Find command:
-
Test the command with realistic text patterns to ensure accurate results.
-
Use the test feature in the command to make sure your regular expression works as expected before finalizing your setup.
-
Include error handling to manage scenarios where the search might not return any results or where the regular expression may not match as expected.
Jump to the example you need:
Find text
This example shows how to locate a specific section of text within a variable and then split the text into two parts based on the character position, storing each part in separate variables.
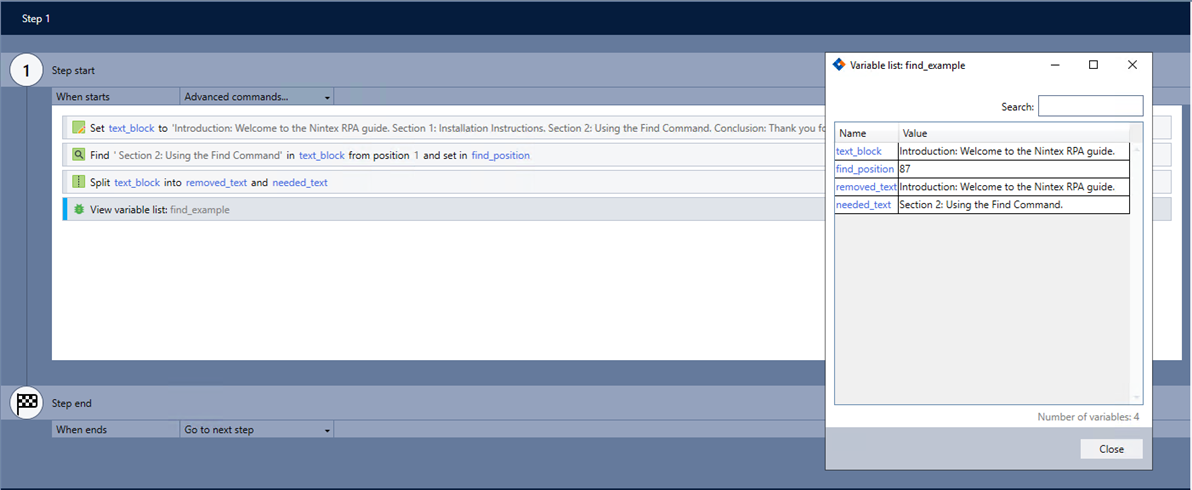
-
Add the Set value command to your wizard to define a variable with the text file (e.g., text_block).
Copytext_block
Introduction: Welcome to the Nintex RPA guide.
Section 1: Installation Instructions.
Section 2: Using the Find Command.
Conclusion: Thank you for reading. -
Add the Find command and complete the following fields:
-
In the variable: text_block
-
Select Find text.
-
Enter Section 2: Using the Find Command. (Note the space before "Section.")
-
Search start position: 1
-
Search direction: Select Start to end.
-
Select Allow close match at 100% accuracy.
-
Return the result in: find_position
-
-
Add the Split command and complete the following fields:
-
Split: text_block
-
By character position: $find_position$
-
Select from the start.
-
Into the variables: removed_text and needed_text
-
-
Use the View variable list command to verify the command works as intended.
Find text matching a regular expression: Full match
Scenario: Extracting email addresses from a block of text using Full match
Suppose you have a large block of text, such as from an email or document, and you want to extract all the email addresses present in the text. This can be useful when you need to gather contact information from a lengthy message or document.
-
Add the Set value command to your wizard to define the text you want to search through.
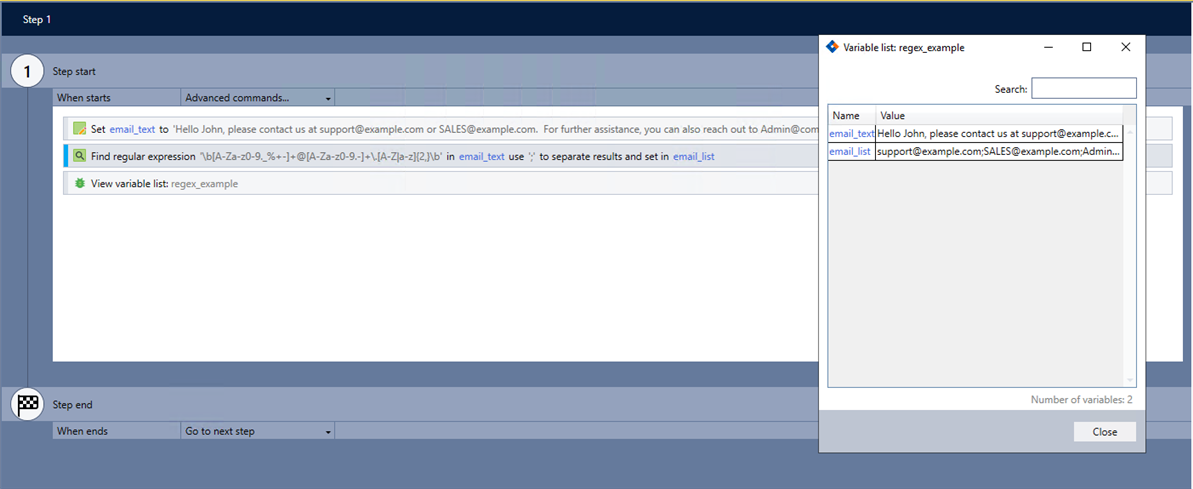
Copyemail_text
Hello John, please contact us at support@example.com or SALES@example.com.
For further assistance, you can also reach out to Admin@company.org. -
Add the Find command and complete the following fields:
-
In the variable: email_text
-
Select Find text matching a regular expression.
-
Search type: Full match
-
Pattern: \b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b
-
Match delimiter: ;
-
Regex options: Since this pattern is designed to match email addresses regardless of whether they are in uppercase or lowercase, the Ignore case option is not necessary. You can leave it at the Default or choose no options. The pattern will still match both uppercase and lowercase email addresses as intended.
-
Return the result in: email_list
-
-
Use the View variable list command to verify the command works as intended.
Find text matching a regular expression: Capture groups
Scenario: Extracting product names and prices from a block of text using Capture groups
Suppose you have a list of product details in a block of text, where each line contains a product name and its corresponding price. You want to extract both the product name and price, and store them separately.
-
Add the Set value command to your wizard to define the text you want to search through.
-
Add the Find command and complete the following fields:
-
In the variable: product_text
-
Select Find text matching a regular expression.
-
Search type: Capture groups
-
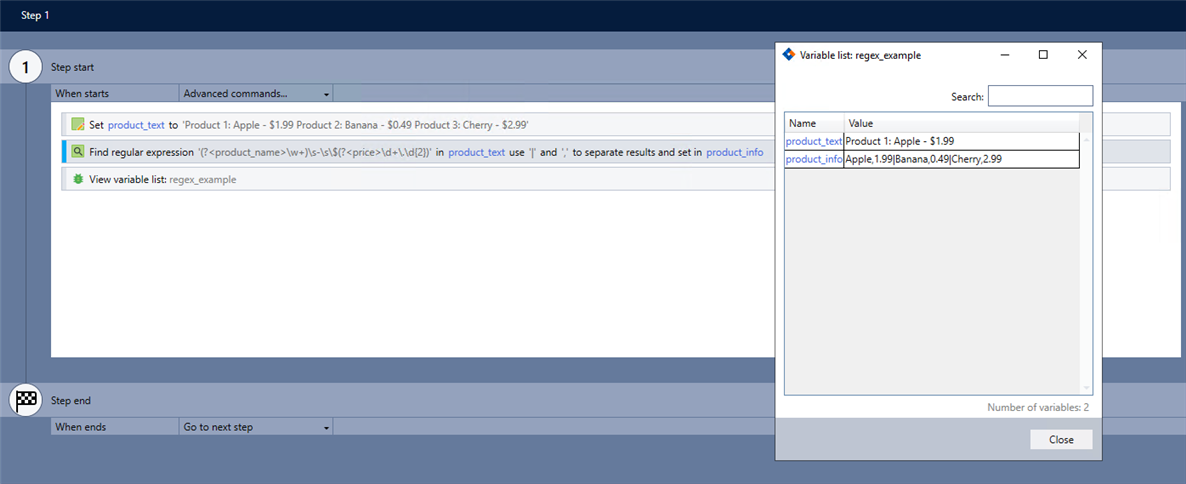
Pattern: (?<product_name>\w+)\s-\s\$(?<price>\d+\.\d{2})
-
Group delimiter: |
-
Match delimiter: ,
-
Regex options: No need to adjust since the pattern is not case-sensitive by default, and we want to match the exact case of the text.
-
Return the result in: product_info
-
-
Use the View variable list command to verify the command works as intended.