High Availability
High Availability focuses on an organization's systems, the level of importance they represent and the acceptable level of downtime that can be tolerated in terms of data loss and productivity.
Examples of component failures are:
- Specific hardware failure such as that of server memory, disk drive(s), power supply, etc.
- Operating system or other software failures.
The key point here is that these are systematic failures, not external, physical catastrophic events. The goal of High Availability is to identify the key elements within a platform that have the potential for failure, then determine a means to build redundancy that can accommodate some level of component failure. Within the K2 platform, the main items that need to be accommodated in an High Availability plan are:
- K2 server(s)
High Availability within the K2 platform typically begins with load balancing. With load balancing, multiple identically powered and configured K2 server nodes act as one logical server. Load balancing uses a hardware or software device to dynamically distribute the flow of incoming TCP traffic to the individual server nodes according to traffic handling rules. Load balancing provides a highly available and scalable platform. If one node becomes unavailable, the load balancing can be configured to direct all traffic to the other nodes for continued processing.
K2 provides detailed instructions for configuring operations within a Windows Network Load Balanced (NLB) environment. If there is a need to work within a hardware load balanced environment, the concepts in these NLB steps should be leveraged to align with the specifics of the target hardware load balancer.
Load balancing is a form of horizontal scaling (sometimes referred to as “scaling out”). Adding more servers to the farm adds more threads for user and workflow requests, however it does not necessarily improve response time unless each node in the load balancing farm is maxed out on resources. Vertical scaling (also referred to as “scaling up”) by adding more powerful processors and more memory can be used to improve response time for situations where nodes of a load balancing farm are not maxed out, and the goal is to improve performance; vertical scaling does not improve availability. - K2 product database
Regardless of the number of server nodes within a K2 instance / farm, there will only be one K2 product database. This database resides within SQL Server. In order to achieve High Availability at this tier, the SQL Server should be clustered (or implement AlwaysOn) for high availability. The SQL cluster can be configured such that if one node fails, the other node can handle processing until the situation is corrected. Thus, SQL Server clusters provide high availability and fault tolerance for mission-critical database applications. For more information on AlwaysOn, see the TechNet article AlwaysOn FAQ for SQL Server 2012.
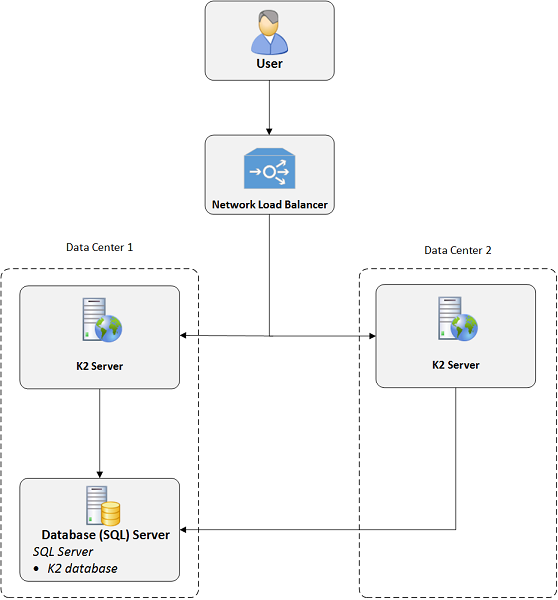
It is important to note that all components of the K2 product platform should reside within the same datacenter. Or put another way, K2 does not advocate having individual K2 server components of one logical farm be distributed across different datacenters. K2 is a database intensive application and requires as fast and low-latency a connection to the SQL database as possible. Accordingly, a configuration like the one below is not a recommended architecture due to potential performance implications:
- Non-K2 products, services and line of business systems
Each of line of business (LOB) system that the K2 platform interacts with must be identified, then reviewed to understand and plan for proper High Availability approach. Failure to include this level of planning and execution may leave the overall K2 landscape in a reduced state of High Availability.
External LOB system interactivity should be captured for each K2 platform instance. This can be used to ensure all external systems are factored into the planning.