K2 Concepts - XML Basics
XML - Extensible Markup Language - is used to describe documents and data in a standardized text-based format. XML provides a powerful and robust framework for data transfer in that it:
- Is simultaneously human- and machine-readable
- Supports Unicode, allowing almost any information in any human language to be communicated
- Is able to represent the most general data structures: records, lists and trees
- Is self-documenting format that describes structure, field names and specific values
- Adheres to strict syntax and parsing requirements that allow parsing algorithms to remain simple, efficient, and consistent
XML Basics
The strength of XML lies in the flexible hierarchy of the data structures it provides. The rules of XML consist of a simple set that focus on standardizing the way in which data is organized without limiting the content in anyway. A simple analogy is a language with a strict grammar but where the words are made-up as required by its speakers.
Specifically it is important to understand:
- The building blocks of an XML document: Tags, Elements, Attributes and Text
- The grammar of the document - the definition of Well-formed XML
- Re-use of data structures through the use of XML Namespaces
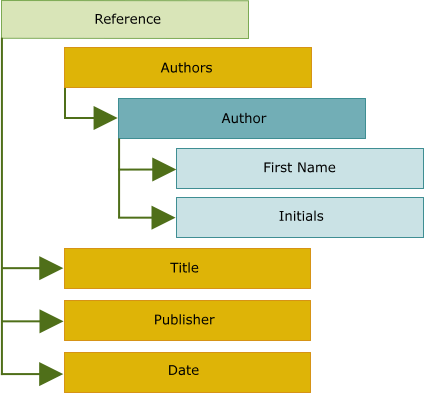
Fig.1. Hierarchy for a Book Reference
Tags, Elements, Attributes and Text
The basic XML structures are best understood in the context of an example information set. Consider a bibliography with two book references in:
- Iacone,SJ. Write to the Point. Career Press. 2003 (ISBN: 1-56414-639-1)
- Benz, B; Durant, JR. XML Programming Bible. Wiley Publishing, Inc. 2003 (ISBN: 0-7645-3829-2)
Each record consists of an author listing (Last Name, Initials) , the title of the book, the publisher and the year published - additionally the ISBN uniquely identifies each book. It is then possible to construct a data hierarchy for a Book Reference Record as shown in Fig.1.
The associated XML definition is shown in the code sample. The key elements of the definition includes:
- Tags - begin with a < and end with a >
- Elements - take the form
<element></element>examples from the code sample include<bibliography></bibliography>,<reference></reference>,<authors></authors> - Attributes - list additional information about the element, which need not be displayed, examples from the code sample are
id="1",isbn="1-56414-639-1" - Text - represents the actual data value associated with an element, e.g. the title of the first book is "Write to the Point", and appears between the title element tags -
<title>Write to the Point</title> - Comments - make it easier to understand the code and are framed by <!-- and -->
e.g.<!--Author Listing-->
 Copy Copy |
|---|
|
<!--XML Definition for a Bibliography--> <bibliography> <!--First Book Reference Start--> <reference id="1" isbn="1-56414-639-1"> <!--Author Listing Start--> <authors> <author> <last_name>Iacone</last_name> <initials>SJ</initials> </author> </authors> <!--Author Listing End--> <title>Write to the Point</title> <publisher>Career Press</publisher> <publish_date>2003</publish_date> </reference> <!--First Book End--> !--Second Book Reference Start--> <reference id="2" isbn="0-7645-3829-2"> <!--Author Listing Start--> <authors> <author> <last_name>Benz</last_name> <initials>B</initials> </author> <author> <last_name>Durant</last_name> <initials>JR</initials> </author> </authors> <!--Author Listing End--> <title>XML Programming Bible</title> <publisher>Wiley Publishing, Inc</publisher> <publish_date>2003</publish_date> </reference> <!--Second Book End--> </bibliography> <!--Bibliography End--> |
Well-formed XML
XML has core set of format requirements in order for XML to be considered well-formed. This is the grammar of the language referred to above.
General formatting rules for XML are:
- XML is case-sensitive
- An XML document may have only one root element. The root element in the example above is <bibliography></bibliography>
Elements
The following are the rules for elements, according to the XML standard:
- Naming conventions:
- Element names may contain letters, numbers, hyphens(-), underscores(_) periods(.) and colons (:)
 |
Colons should only be used when a namespace has been defined. See namespaces below for more detail |
- Element names may not contain spaces (underscore typically used to replace spaces)
- Element names may start with a letter, underscore or colon but may not start with non-alphabetic characters, numbers or the letters xml
- General format:
- Each opening tag must have a matching end tag e.g.
<title></title> - or be self-closing (empty) e.g.
<img src="images/example.gif" /> - Tags may not overlap. The following is not well-formed XML:
<p>This text is <b>not <em>well-formed</b> or valid</em> XML</p> - Elements may be empty
 |
XML provides a shortcut for empty elements, <empty_element></empty_element> can be written as <empty_element/> |
Attributes
- Attributes follow the same naming conventions as elements
- Attributes are defined in terms of a name and value pair
- Attribute definitions follow the format attribute_name="attribute_value" where the value can be enclosed in matching single quotes (') or double quotes (")
e.g.id="2",isbn="0-7645-3829-2"
|
Attribute Values can contain apostrophes as long as they are framed by double quotes. e.g. source="Roget's Thesaurus" is valid |
- Attributes are defined in the opening tag of an element
- Attribute names cannot be repeated within the same tag
- Attributes are unordered, that means the order of attributes within a tag does not matter
Text
Text usually represents the actual data associated with an element. The only considerations for text center around whitespace (spaces, tabs, etc.) which makes the document more readable and troublesome characters (like &,<,>,",') which may confuse an XML parser
- Whitespace is preserved in XML - that means
<element>Hello- -World!<element>is not changed to<element>Hello--World<element>but remains the same - New Line characters (Shift-Enter or <br>) are replaced with Carriage Return characters (Enter or <p></p>) to ensure consistency across all platforms
- The following characters are used frequently within the definition of an XML document and are preferably eliminated from the text by using their entity references:
-
- & - the ampersand (&) character
- < - the less than (<) character
- > - the greater than (>) character
- ' - the single quote or apostrophe (') character
- " - the double quote (") character
Comments
Comments make it easier to understand the XML document and must adhere strictly to the format:
<!--comment-->
|
|
In the example above all comments are shown in green. e.g. <!--XML Definition for a Bibliography--> and <!--First Book Reference-->
XML Declaration
The XML Declaration identifies the document as an XML document, and although not required it does provide important information to any program trying to interpret the XML file.
The XML Declaration takes the following form:
<?xml version="1.0" encoding="UTF-16" standalone="yes" ?>
- Version (required) refers to the version of XML standards used in the document, usually version 1.0
- Encoding (optional) sets the text encoding format that will be used to represent characters. XML supports Unicode and defaults to using UTF-8 or UTF-16. It is through these character sets that XML is able to offer support for non-Latin alphabets (e.g. Arabic, Chinese, Japanese scripts) and other symbols
|
UTF stands for Universal Character Set Transformation. UTF-8 uses an eight bit encryption of the character set , UTF-16 uses a 16 bit encryption of the character set. More detail on Unicode formats available is available from www.unicode.org |
- Standalone (optional) specifies the external dependency of the document:
- Standalone="yes" means that the document does not require additional XML documents to be interpreted, i.e. all its definitions are self-contained
- Standalone="no" notifies the reader (machine or human) that the document may require other documents to be fully understood, i.e. it may include other files and use definitions from such files. The standalone value is no by default
XML Namespaces
Namespaces differentiate elements and attributes defined in different documents or related to different data sets. They help to ensure the uniqueness of element and attribute names which is important when sharing information between different applications or even publicly.
Additionally, it helps to identify information groups and types within the current document.The bibliography example above is extended to include a basic namespace declaration:
| Copy |
|---|
|
<--The XML Declaration--> <?xml version="1" encoding="UTF-16" standalone="no"> <--Definition of the Root Element including a Namespace Declaration--> <bibliography xmlns:bib="http://www.k2workflow.com/bibliography"> <!--First Book Reference Start--> <bib:reference bib:id="1" bib:isbn="1-56414-639-1"> <!--Author Listing Start--> <authors> <author> <last_name>Iacone</last_name> <initials>SJ</initials> </author> </authors> <!--Author Listing End--> <bib:title>Write to the Point</bib:title> <bib:publisher>Career Press</bib:publisher> <bib:publish_date>2003</bib:publish_date> </bib:reference> <!--First Book End--> ... |
The following changes in the XML code sample are important:
- The XML namespace declaration (
xmlns:bib="http://www.k2workflow.com/bibliography") has three distinct parts:
- The reserved declaration prefix - xmlns
- The namespace prefix - bib - which identifies any descendent elements
- The Universal Resource Identifier (URI) which can either be a URL (Universal Resource Locator) or a URN (Universal Resource Name) - http://www.k2.com/bibliography
|
Typically URLs are used as the URI to uniquely identify namespaces. It is, however, not required that this link to an actual file |
|
There are public namespace URIs, including: - xmlns:html="http://www.w3.org/1999/xhtml" - xmlns:xs="http://www.w3.org/2001/XMLSchema" - xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" |
- The namespace applies to the element it has been defined in and all its descendents. In the example bib is automatically the default namespace for authors,author, last_name and initials
|
To cancel the default namespace for an element include an empty namespace declaration, e.g. name in the following code snippet<p xmlns:html="http://www.w3.org/1999/xhtml">I met <name xmlns="">John David</name> on holiday |
- The namespace can been specified for descendent elements and attributes using the namespace prefix in the element name. In the example bib is specified as the namespace for title, publisher and publish_date elements; and for the id and isbn attributes by using the bib prefix in their names e.g.
<bib:title>andbib:isbn="1-56414-639-1"
|
This is not a comprehensive introduction to XML - but rather an orientation to XML as used in K2 |
